Ostatnie dwa odcinki mojej domowej devopsowej epopei doprowadziły mnie do fajnie działającego deploymentu aplikacji z bazą danych. Uwzględniając zabezpieczenie wszelkich danych uwierzytelniających (kredek) - tak jak to powinno wyglądać, co do zasady. Ale to nie wszystko..
Usprawnienia deploymentu
W międzyczasie, usprawniłem i poprawiłem specs file dla deploymentu aplikacji z MongoDB, tak aby temat był ogarnięty w jednym jobie a aplikacja została uruchomiona wtedy i tylko wtedy kiedy stan zadania deploymentu MongoDB jest healthy. Ta technika w świecie Nomada nazywa się prestart side-car. I MongoDB jest takim side-carem.
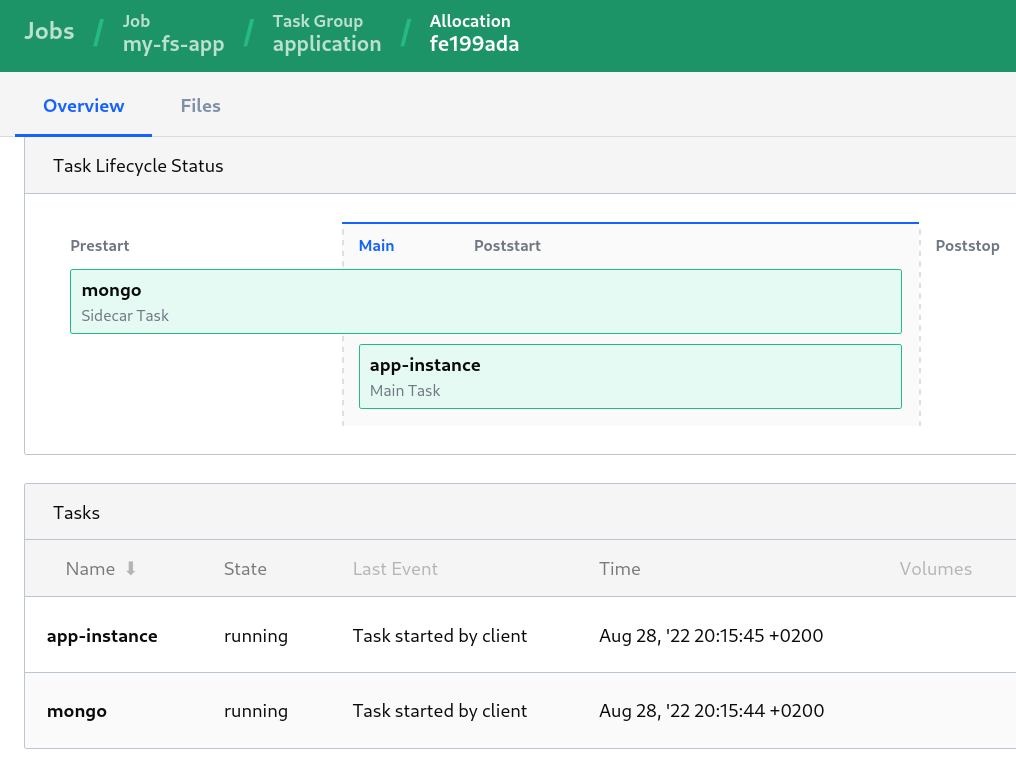
Jak widzimy, side-car może być uruchomiony jako:
- prestart - zanim uruchomimy co innego, ten musi działać, bez niego nic dalej nie pójdzie,
- poststart - wjeżdża po tym jak główne zadanie - aplikacja - zostanie uruchomiona,
- poststop - uruchomione po tym jak główne zadanie przestaje działać, np. jakieś zadanie “sprzątające”
A tu jest specs file. Prócz skonsolidowania dwóch odrębnych deploymentów w jednej grupie jako dwa zadania; to pierwsze - dla Mongo ma dodatkowy wpis:
1
2
3
4
5
6
lifecycle {
sidecar = true
hook = "prestart"
}
Bez tej zmiany, oba zadania nadal są zależne od siebie, ale bardziej jako towarzysze niedoli - jeśli którekolwiek z zadań jest unhealthy i koniec końców umiera (status: dead), to nomadowy scheduler widząc to, solidarnie uśmierca też to już działające. Co oczywiście zabiera mu trochę czasu, generuje logi, komunikaty i trochę komplikuje troubleshooting. Stąd wynikło ulepszenie a to przy kolejnym zadaniu związanym z dostępnością ułatwi zabawę. Dlatego tak zdefiniowany deployment będzie bazą do dalszych rozważań i usprawnień. Na przykład do tego, by rozbić oba serwisy na dwie grupy, tak by można było utworzyć kilka instancji aplikacji (a niekoniecznie już MongoDB).
Co z tą dostępnością?
Kolejnym etapem dbania o bezpieczeństwo aplikacji jest zapewnienie jej dostępności (jeden z wymiarów bezpieczeństwa). Wypadałoby postawić jakiejś reverse-proxy, na podstawie nagłówków sprawdzić czy zapytanie jest Ok, przekierować (ang. upstream) do właściwego serwisu, trzymać sesję itd. Generalnie są trzy scenariusze, jak można to zrobić:
- albo wykorzystując jeden główny rev-proxy dla całego klastra Nomadowego z auto-skalowaniem (w ramach pojedynczego data-center, ang. ingress),
- albo wykorzystując technikę side-car i dać aplikacji jej własnego i osobistego rev-proxy w ramach pojedynczego deploymentu,
- albo ulepszony scenariusz pierwszy - tzn. na każdym serwerowym węźle lokalnego klastra Nomadowego postawić rev-proxy, ustawić round-robin w DNSie dla pojedynczej nazwy klastra i ustawić rozproszony load-balancing temu proxy, poprzez konfigurację Consula.
Jak wszystko, te podejścia mają swoje wady i zalety. Przy pierwszym podejściu - “wiadomix” - pojedynczy punkt awarii, jak nam ten ingress siądzie to kicha z dostępem do wszystkiego co tenże proxy obsługuje. Z drugiej strony jeden proxy, jeden payload, jeden proces/kontener. Łatwo się kontroluje, mało zasobów zżera Nomadowi et consortes (+Consul i Vault). Drugie podejście ma odwrotnie - jak się popsuje, to nie działa jedna appka z wielu, ale też tych proxiaków możemy mieć poupychane w klastrze na tyle ile mamy tych aplikacji. A zatem, to rozwiązanie nadaje się na np. deployment pojedynczego autonomicznego klastra z aplikacją w AWSie. Najfajniej byłoby mieć to trzecie rozwiązanie - czyli stoją sobie proxy na każdym węźle, user robi deployment na adres Nomada, np. nomad.mojadomena.com, robi się aktualizacja konfiguracji proxy o nowy upstream e voila!. To ostatnie podejście jest najbardziej skomplikowaną sprawą do konfiguracji. Celowo tutaj nie wspominam jeszcze o obsłudze certyfikatów, żeby nie komplikować. Po kolei.
Nomad z Consulem, czyli po polsku ;) - orkiestracja z mesh-em (sic!) są w stanie obsłużyć wszystkie te podejścia z wykorzystaniem najpopularniejszych proxy: NGINX, HA-Proxy, traefik i envoy. Przy czym ten ostatni jest w pełni zintegrowany w taki sposób, że wystarczy “hokus-pokus” (z wykorzystaniem Consul Connect) w specs file-u nomadowym i mamy serwis obługiwany poprzez envoya w ramach pierwszego scenariusza. Natomiast ja wolałbym się zająć, już tradycyjnie komplikując sobie, tym ostatnim scenariuszem. Przypomina to taki systemowy ingress kubernetesowy (np. NGINX), gdzie wszystko definiuje nam helm chart i odpowiednie annotations,a my tylko robimy deployment i hyc! ..pod wskazanym URI odnajdujemy nasz serwis.
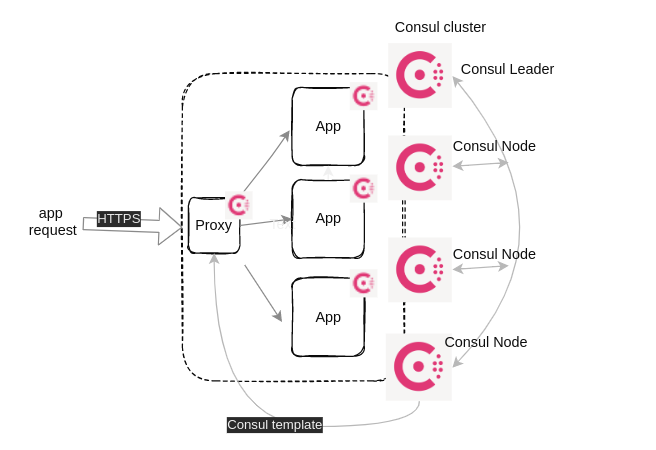
Poniżej diagramy przedstawiające poglądowo scenariusz, który chcę zrealizować i opisać w kolejnej części - a będzie tego sporo: grzebanie w konfiguracji Nomada i Consula, poprawnie zestawione TLSy między komponentami klastra, integracja, consul-template, przykładowe problemy do troubleshootingu, przykłady spraw niejasno opisanych w dokumentacji, konfiguracja proxy i na koniec certyfikaty. Fajnie byłoby mieć gotowe PKI na Vaulcie, ale to na razie w planach, jako wisienka na torcie.
Diagram logiki rozwiązania - Nomad odpali kontenery z proxy i z instancjami aplikacji na runtime dokerowym
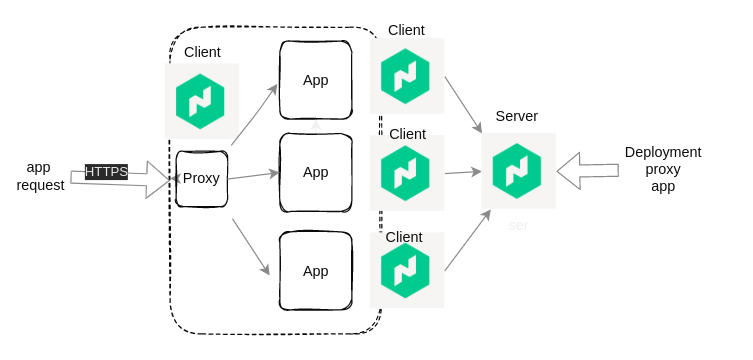
Diagram logiki sieciowej (usługi Consula) - usługi przy deploymencie zostaną zarejestrowane w Consulu przez Nomada z informacjami o IP, portach, healthcheck-ach, a proxy przy pomocy Consul template zaktualizuje swoją konfigurację.