Throughout my short DevOps team member and manager career I used to take notes. All in English. Hence this post in English. It outlines some thoughts and experience gathered along the line confronted with hints and knowledge taken from good readings I studied. The readings are listed at the end of this post.
Thoughts on some DevOps improvement tactics
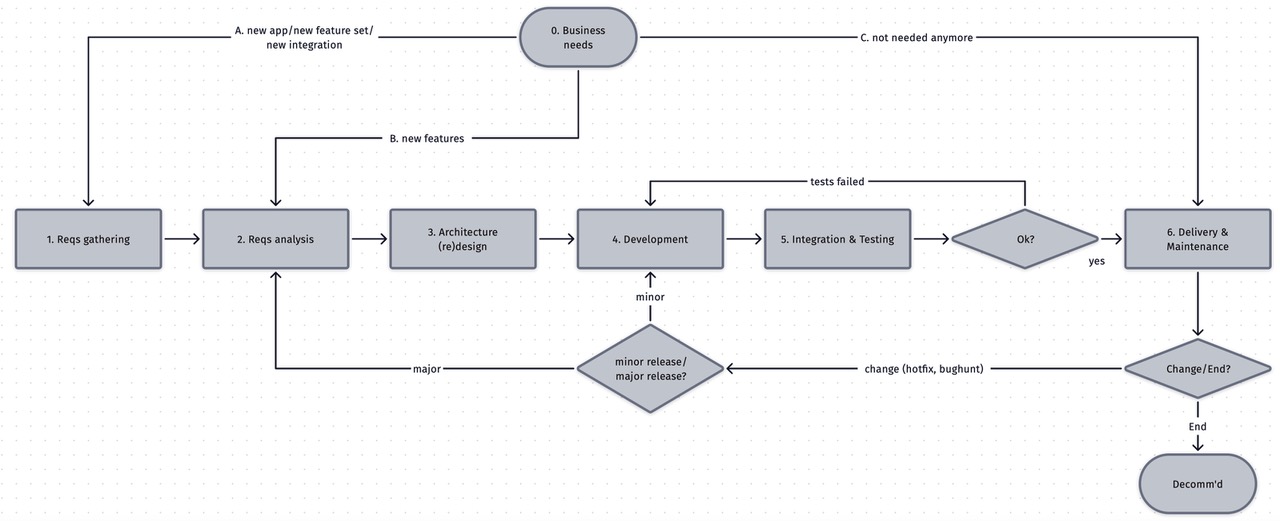
A migration is often a painful process. Especially migrating some old applications along with the delivery process around them to a new platform featuring all those modern bells and whistles (like AWS/Azure driven Kubernetes or HashiCloud Platform etc.). And it does not only convey switching the technology from A to B (or lift-shift), nor only focuses on writing a new set of procedures (playbooks) on how to do things on Platform B - either. It actually requires a thorough refinement of the SDLC process, which all teams engaged and involved in this process should follow in their daily work to benefit from the new platform and make the migration meaningful and cost controlled.
A bit of background - a very common story
Imagine that once, the whole software delivery was a model of four teams - the architects, the development team, the Q/A team and the maintenance team. Each managed independently. Of course there were also some business analysts who were shovelling the requirements to the architects. They all followed a sequence of hand-offs to get the apps to production. However, there was no automation in place. The architects were making nice looking drawings in PPT, discussing some non-functional requirements with (totally separate, living on another planet) security dudes and that was it. The PPT diagrams were then handed over to the development team, who led by a PM and business relation analysts were taking care for functionalities to be cranked out of it. The developers were working on their own separate branches (multi-branch approach). So, once a specific functionality was announced done, it took a while merging those branches to the main one. Then Q/A was taking care of testing for weeks.. or months. When they were happy a release took place and if it worked bottles of champagne could be put to an ice bucket and celebration of a release could start. After those (rare) moments of sheer joy, the app was then handed off to the maintenance team, who were to support the app, handle issues reported by the users. Yet, they had no idea how the app was designed, developed and tested. They operated through playbooks.
Unfortunately, while the process looked orderly and coherent, it had certain flaws due to siloed teams and the way the communication across the SDLC process functioned. Even though, the Agile methodology was introduced, it had very limited impact on efficiency and productivity, mainly because only the development team alone followed the agile principles with all those sprints and stand-ups. While the maintenance followed through tickets in mainly a reactive mode. That all being said, resulted in perception of the reality around a given app - it was either in project-driven state (new functionalities were developed and old bugs being remediated) or in a business as usual mode where only maintenance teams were actively operating around the app, while the other teams already jumped out to another projects. Neither reality fit the Continuous Delivery model.
What was wrong in this picture?
- The architects position was so low in the process, that once their job was done and the design was handed off to the developers, they were never given any feedback and never had any say (as not being involved) in subsequent sprints onward regarding new functionalities, design flaws, enhancements etc.
- The only pattern the architects followed was a PPT pattern. There we no design pattern and components were largely determined by the business expectations and business analysts advocacy towards certain technology stacks.
- The developers considered diamonds in the crown, were essentially cranking out new features, not quite caring of the code quality, tech stacks, libraries, security nor were they using any advanced tooling beyond their IDE on laptops (Visual Studio Code).
- The Q/A were testing things manually, which lasted weeks and months.
- The maintenance team, disconnected from the design and development phases were handed off just a piece of software being told what to do (scope limited to the playbooks they were given).
- There was a separate ticketing system for developers and maintenance teams.
- No continuous delivery was actually happening, although Jenkins and Docker orchestration with some monitoring was in place.
So, did the Jenkins pipelines, some basic Docker orchestration, Agile development and some monitoring establish any DevOps practise? The answer is: No. Not at all. It’s just a good starting point.
Why? A common platform was indeed in place (the Docker orchestration) where the apps landed, built and pushed through Jenkins pipelines. Yes, but all profound principles of DevOps were still missing, undermining the whole effort. Some tech/Linux savvy architects had built the platform and set up the pipelines. Hence, effectively all the components were commodity operated on daily basis without any thoughts on improvements going forward.
Symptoms, gaps
The “DevOps” is just a term, a buzzword. Can be meaningful or meaningless. Like Agile, if best practises are not followed within the entire delivery process setup, it’s miserably falling into old days Ford’s assembly line model - I did my part, now you do yours, bye. Regardless how agile a given organisation looks on a powerpoint presentation, these below are signs (or metrics) that Agile in the core development phase of the SDLC does not bring expected benefits:
- the organisation is unable to act quickly upon critical bugs or vulnerability found,
- the organisation is unable to provide frequent successful deployments on daily basis,
- the organisation is unable to act frequently, so that delta between changes is kept low, hence less risky for any potential piled up faults,
- the deployment process is not transparent to the user community (downtime announcements),
- the organisation is unable to bring and test new feature within 24h after a standup.
Gaps
The above listed are symptoms. And usually what it means is that there are certain (and very common) gaps at the operational and technical layers of any given DevOps to-be-driven environment:
- designs of the apps handled through the DevOps driven process are either outdated, non existent, or not consulted and agreed with the relevant IT architects (proper design and changes to the design must be a prerequisite for any further proceeding across the CI/CD),
- no automated tests in place - unit tests, acceptance tests, integration tests, security tests, smoke tests; or at least their coverage is not satisfactory,
- teams do not truly works together (there’s no real devops philosophy in place of a shared responsibility),
- long technical debt tail, long time spans between updates and upgrades (if any were in place),
- outdated documentation,
Real cases
Let’s see what it all means in real world:
- Case 1: At any given moment the organisation is unable to provide a successful production deployment, due to outstanding vulnerabilities in the codebase, which makes one of the quality (security) gate blocking the release, effectively stalling the deployment.
- Case 2: At any given moment, the organisation is unable to patch up and test a deployment, because there are no automated post-commit checks which would catch all outstanding discrepancies and overall quality posture.
- Case 3: Faulty deployments are handled ex-post, upon users community feedback; yet without any traces back in the CI/CD steps. And it requires hours to troubleshoot efforts to find a root cause.
- Case 4: Developers and/or Q/A manually test things with no quick feedback featured across the delivery process.
Also, often teams although empowered by visibility and controls do not feel responsibility for the design, quality, testing and deployment. They do not feel it’s a loop and that any single prod deployment does not ends their mission.
Some improvements
To engage with the DevOps philosophy and gradually improve the awareness and fluency across the teams, a dedicated and devoted DevOps team had to start from themselves. Let’s see it as a DevOps center of excellence at its very infancy. The team’s main purpose was:
- be a platform (or XaaS) team - helps the other teams to overcome obstacles while working towards successful (more secure, quicker, more stable) software delivery. Also, they were up to detect and identify flaws, deficiencies and missing capabilities. And to promote enhancements and mindset shifts across the table. The main way of communication in this role is : component as a service (Jenkins, Docker orchestration, Vault etc.) offered to other teams use, for all components of the platform.
- be the Enablers - beyond what they were up to wearing the “Platform” hat, they provided a steady and upward learning curve delivering new/improved components, techniques and products to accelerate the delivery process. Showcasing them and explaining profits to the other teams.
Given these two major roles of the DevOps team, they managed to establish some specific way of communication. Which also had positive impact on outlooks for successful development of DevOps practices. There were four main ways of communication they were trying to establish (really, everyone talking to everyone is not the best idea):
- Collaboration, based on daily routines, pieces of sprints, and other tasks - the DevOps team collaborates on daily basis using available instant communication means like Zoom, Teams, Slack channels, virtual boards. It’s important to record these efforts through JIRA or the likes.
- X-as-a-service, this model of communication is largely streamlined through dedicated ticketing system board to measure overall improvements and enhancements of the whole DevOps eco-systems put together encompassing a bunch of components/services.
- Facilitators, advocating, helping, showcasing the other teams the enhancements, introduced principles (like semantic versioning, docker image optimisation techniques), good practises and methodologies (like Trunk Based Development) or changes impacting daily routines of the other teams. Zoom & Teams.
- Writers, finding a common platform to host all necessary documentation, tagged and sorted out appropriately, supported by a search engine. So, that during any talks, discussions any good pattern to follow, any how-to write-up, design or tech structure can be found, referred to and understood broadly. A platform like Wiki would be helpful. Sharepoint is awful for this kind of stuff, but doable.
Considerations before taking on a migration
The apps
Usually there are variety of flavours and designs of the running apps across the organisation. Their architecture, technology differ from one another. Nevertheless, let’s group them up and later, propose a possible approach to tackle issues and problems associated with the modernisation and migration to the “new default” given the app’s tech stack.
Windows Realm:
- Apps developed in .Net, codebase stored in TFS, built locally on a programmer’s machine & IDE. Deployed straight to non-prod/prod WinTel server with IIS. Largely a monolithic design, lack of proper documentation. Some integration with back-end MS SQL or other MS oriented services. The apps often suffer from lack of proper documentation, standardised security controls, no automated testing, and no secure coding practises. Deployments take place occasionally with many teams around engaged to address issues.
Open Source Realm:
- Apps developed using open source stacks like popular Node.JS+Angular, and the likes. Some already docker-ized run on Docker swarm or just on a docker runtime. Most of those IDE environment consist of defined Jenkins pipelines, however there’s no clear evidence on using only declarative pipelines, some of them are outdated and or not properly maintained. Often these apps are integrated with other Open Source components like MongoDB, PostgreSQL, Kafka etc. The codebase is stored at some git driven repositories (Gitlab, BitBucket, TFS). Active development is in place, hence the support is somewhat more reliable in terms of updates, testing and upgrades. None the less, automated testing is scarce, and no coherent best practises in coding or security is in place (secrets are stored in Jenkins, git repository, local programmer’s computer etc.).
One of the most prevailing advantages of moving into containerisation in Cloud is leveraging and driving modern and secure design, programming (TDD, TBD, DDD) and continuous delivery approaches. Ensuring appropriate security are in place in both CI/CD pipelines and the developed product (security by design).
Strategies
Inspired by some white papers regarding moving-to-the-cloud strategies, some standardised approaches can be proposed given current apps states. They may be considered as a general effort for the modernisation. The 6Rs. Collectively known as the “6R of migration”. Actually some of them can be applicable in most cases:
- Retiring, you just plan decommissioning of the app and designing a new one, from scratch. Also functionality can be replaced by some other app/component(s) being already migrated or augmented by an off-the-shelf purchase to the existing IT eco-system.
- Retaining, you keep the thing as is for determined time span. As a given app is going to be replaced or phased out altogether (by “retiring” approach in future). Associated costs of maintenance as well as other apps or components this retained app integrates with, will also remain.
- Re-hosting, known as “lift and shift” approach, where you move the app as is to the new environment and new platform. Apps with long tail of technical debt will likely incur costs of maintenance to cut the tail and conform to new S-SDLC (quality and security gates).
- Refactoring - and re-architecting if the scope requires some profoundly deep changes of the applications. This approach is usually driven by a need to add features, make the app passable through the new platform quality gates, security checks, automated testing - all leveraging much quicker and transparent deployments and scalability. Refactoring often boosts agility, business continuity, shifted-left security and overall productivity through better collaboration across the teams. However, this strategy tend to be most time and resource consuming.
Best Practises
These best practises should be tirelessly propagated and advertised by the DevOps team. However, a successful migration can be achieved (where a given timeframe and assessed costs are met) through the IT organisation capabilities, which should be capable to ensure the following best practises:
Architecture:
- Precise design using modern methodologies (DDD),
- Precise and standardised design covering all functional and non-functional requirements, clear components lists, specified tech stack (compliant with approved tech stack components), concise and clear diagrams, threat model, identified risks and agreed trade-offs,
- Standardised building components and valid sources (delivery chain security),
- Statelessness of the app components - meaning that the app’s state is not retained within the app, and can be easily scaled out through orchestration platform,
Programming:
- Trunk Based Development (or further monorepo),
- Test Driven Development,
- At least two programmers in the project, to facilitate such good practises like “code review”, “secure branching”, etc.
- Semantic versioning,
- Standardised building components and IDE integrated with modern secure development components like GitGuardian, Snyk, (hashicorp vault), Docker Desktop, other SAST/SCA/DAST scanners, Sonarqube,
CI/CD:
- full automation of all repeatable steps,
- quick and comprehensive feedback from the automated components,
- unit tests, acceptance tests, integration tests, security tests, capacity/load/smoke tests etc.
- Capacity and scalability testing under various load (require business metrics the Kubernetes will act on),
- Frequent small, atomic changes to the codebase (to keep delta at manageable level and make the code reviewers life easier, not to let them review hundreds line of code changes across multiple files),
- Deployments fully transparent to the user communities.
Clear communication channels for the DevOps team:
- Team - enablers/collaborators - working together as time allows to discover and experiment with new solutions, fixes, ideas through technologies, APIs, methodologies, etc.
- Team - Platform/XaaS - provide support for multiple SDLC components - like Jenkins, GitHub, SonarQube, Nomad, Vault, etc.
- Team - Facilitating/performing - showcasing, coaching, lending hand to other teams about changes, shifts, best practises, gradual improvements.
Organisational capabilities:
- Less risk of cognitive overload, so the DevOps and other teams have comfort for deep working, learning and experimenting,
- Keeping the teams project agendas close to one another and the once formed teams are not getting disbanded too often, so that natural engagement in a project does not take long each time it starts (storming, norming, performing),
- Apps grouped up around business areas and business values, so the support teams is not required to spread their limited cognitive capacity across multiple exclusive (constantly evolving) tech stacks.
Further (good) readings
- Dave Farley’s blog should be read frequently, before you take a look at your morning news, get to Dave’s first,
- “Continuous Delivery” by Dave Farley and Jez Humble, an absolute must read!
- “Accelerate - the science of Lean Software and DevOps “ by Jez Humble, Nicole Forsgren and Gene Kim, you should know at least two out of these three names from “the Unicorn Project”,
- “Continuous Delivery blog”, principles and other varia by Jez Humble,
- “Monolith to Microservices” by Sam Newman, if you want to understand and support an old app migration,