Odpowiedź może być jedna - Nomad. A konkretnie Nomad zintegrowany z Vaultem. Ogólnie to plan jest taki, aby kredki do bazy były bezpieczne, nie jakieś tam .env na laptopie developera (w najlepszym wypadku, i tak wrzucane do repo) czy, o zgrozo! w jakimś pliku .txt. Opcje są dwie - albo je przenieść jako secrets do GitHuba w repozytorium aplikacji albo zabezpieczyć tak, żeby nawet programista nie miał o nich pojęcia od początku do końca. Czyli trzeba mu je schować. Jako, że mam tendencje do utrudniania sobie życia, to zrobię to z wykorzystaniem integracji bazodanowego silnika Vaulta z MongoDB.
Use case
Dlaczego tak? Wyobraźmy sobie że mamy klaster niezawodnościowy takiego MongoDB (jakiś wielki ReplicaSet) i tam kilka/kilkanaście baz, a w każdej ileś tam kolekcji ze strasznie ważnymi dokumentami. Albo też, chcemy zrobić deployment aplikacji razem z MongoDB. A do takiej bazy dostęp ma być ustawiony indywidualnie i bezpiecznie. I to jest nasz tzw. use case. I oba scenariusze do tego pasują, ale zajmiemy się tym prostszym - trzeba zacząć od czegoś prostszego, nawet jeśli sobie człowiek sam utrudnia. :)
Do tego celu posłuży nam silnik MongoDB odpalony i skonfigurowany w Vaulcie. Każda instancja bazy będzie miała swoją odpowiednią rolę, politykę nazewnictwa użytkownika, politykę haseł i okres przydatności do spożycia takiego hasła.
Tam właśnie (w Vaulcie) login i hasło będą wygenerowane (z odpowiednim TTL) i zaserwowane Nomadowi, który jako zintegrowany z Vaultem poprzez odpowiednią rolę w Vaulcie przypisaną do tokena (którym Nomad uwierzytelnia się Vaultowi) i swoją funkcjonalność template pobierze je sobie podczas deploymentu aplikacji do odpowiednich zmiennych. Dzięki temu nasza aplikacja przeczyta login i hasło właśnie przez te zmienne. Naturalnie, łebski programista może sobie napisać taką githubową akcję, że te kredki odczyta. No, ale.. ale .. przyzwoicie ustawione środowisko rozwoju aplikacji zapewnia, że ktoś musi zrobić commita i PR-a, ktoś inny tego PR-a przejrzeć i zaaprobować (oby nie). A to wszystko pozostawia swoje ślady w logach i czeka na przeglądy audytowe, bądź ląduje w turbo-inteligentnym SIEMie. W każdym razie, taka akcja nie przejdzie niezauważona. Z kolei funkcjonalność “wskoczenia” sobie do kontenera z UI-a nomadowego też np. dla developerów może (i powinna) być zablokowana, przynajmniej na produkcji.
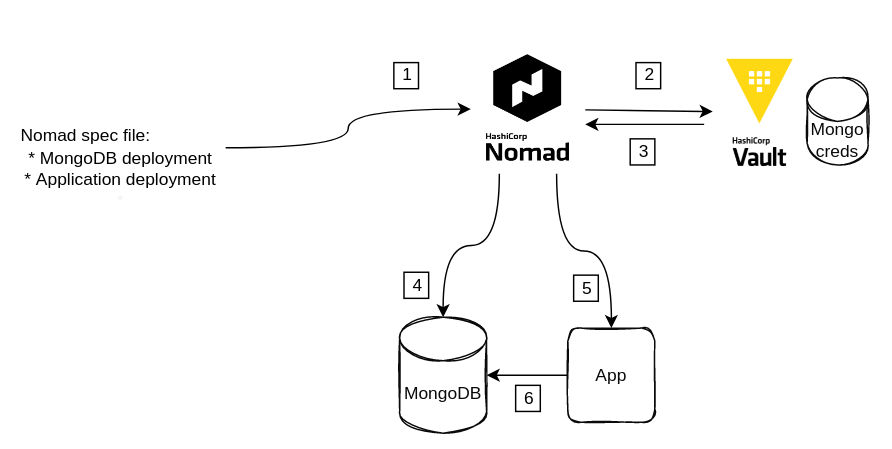
Zgodnie z numerkami na obrazku sekwencja zdarzeń wygląda następująco:
- Leci deployment (ręcznie bądź przez GH Action) do Nomada zgodnie ze specyfikacją (tzw. jobspec file)
- Nomad będąc zintegrowanym z Vaultem, uwierzytelnia się swoim tokenem i pobiera wartości odpowiednich kluczy z odpowiedniej ścieżki,
- Vault te wartości zwraca i Nomad poprzez mechanizm template podstawia wartości do zmiennych,
- Następuje dalsza część wykonania jobspec czyli pobranie obrazu Mongo z rejestru i jego uruchomienie na danym węźle nomadowym,
- Jeśli uruchomienie MongoDB przebiegło poprawnie, kolejnym krokiem w jobspec jest pobranie zbudowanego obrazu naszej appki i uruchomienie podobnie jak z Mongo (może być ten sam węzeł, inny lub do decyzji samego Nomada - tu się przydaje Consul ze swoim mesh-em)
- Aplikacja loguje się do bazy kredkami pobranymi w poprzednim kroku, podobnie jak w przypadku MongoDB.
Czego potrzebujemy na start?
- Klaster Nomada zintegrowany z klastrem Vaulta (Nomad może być też zintegrowany z Consulem, ale nie musi)
- Klaster Vaulta zintegrowany z klastrem Consula (który robi za rozproszony i bezpieczny storage dla Vaulta)
(jak to zrobić jest dość dokładnie opisane tu)
Droga do sukcesu
Integracja Nomada z Vaultem jest dość prosta do skonfigurowania i dość dobrze opisana w dokumentacji Hashicorpa. Najważniejsze są polityki i role - jedna nomad-server-policy.hcl dzięki której serwer Nomada będzie miał odpowiednie uprawnienia do komunikacji z Vaultem, automatycznego odświeżania tokena itd., a druga mongodb-access-policy.hcl która umożliwi klientowi Nomada dostęp mu do naszych tytułowych kredek MongoDB podczas operacji deploymentu. Kolejnym ważnym elementem jest rola przypisana do tokena (nomad-cluster-role.json), której po przypisaniu podczas wygenerowania tokena nie da się zmienić, w tym sensie - że po takiej zmianie, trzeba wygenerować nowy token. Spójrzmy na tę rolę po jej przypisaniu do tokena - allowed_policies i disallowed_policies:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
$ vault read /auth/token/roles/nomad-cluster
Key Value
--- -----
allowed_entity_aliases <nil>
allowed_policies []
allowed_policies_glob []
disallowed_policies [nomad-server]
disallowed_policies_glob []
explicit_max_ttl 0s
name nomad-cluster
orphan true
path_suffix n/a
period 0s
renewable true
token_explicit_max_ttl 0s
token_no_default_policy false
token_period 72h
token_type default-service
Te wpisy mówią tyle, że żadna instancja klienta Nomada nie może używać tego tokena do tego co wolno serwerowi Nomada, ale może wykorzystywać wszystkie inne istniejące w Vaulcie polityki dostępowe (dlatego allowed_policies jest puste), właśnie poza nomad-server. Jak wiemy, całą robotę deploymentu wykonuje klient Nomada, a nie serwer (ten tylko decyduje gdzie). I tutaj miałem jednak lekki “zaciach”. Musiałem zmodyfikować nieco podejście do tego ustawienia - stąd pojawiła się druga polityka mongodb-access, bo inaczej klient Nomada nie miał żadnej innej polityki do wykorzystania, poza default.
Dlatego też, kiedy już wrzucimy tę druga politykę (CLI - vault policy write.. albo UI), w sekcji vault specyfikacji naszego deploymentu MongoDB musimy podać politykę wykorzystaną do sięgnięcia po kredki w Vaulcie (linia 49) i dalej zdefiniowana całą operacja do linii 62 włącznie.
Kredki do bazy w Vaulcie
Te dane, które są nam potrzebne do uruchomienia samego MongoDB zostały zdefiniowane w zwykłym silniku Vaulta - kv (Key/Value store). I zapisane w wersji drugiej (version 2). Dzięki temu mamy historię zmian. Pojawia się wtedy jednak pewna trudność, bo “fizyczne” ścieżki do danych zmieniają w stosunku do tych, które trzymane są w kv w wersji 1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
vault kv get kv/mongo
== Secret Path ==
kv/data/mongo
======= Metadata =======
Key Value
--- -----
created_time 2022-06-12T20:57:20.751883164Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 3
=============== Data ===============
Key Value
--- -----
MONGO_INITDB_DATABASE ****
MONGO_INITDB_ROOT_PASSWORD ****
MONGO_INITDB_ROOT_USERNAME ****
Troubleshooting
Jeżeli mamy nie dość dokładnie skonfigurowane klastry - np. w konfiguracji Vaulta mamy wpisany adres z http a używamy https lub odwrotnie, sa problemy z certyfikatami .. to przy deploymencie w kroku dry-run czyli np: VAULT_TOKEN=<..> nomad plan mongodb2.nomad może pojawić się dość enigmatyczny komunikat:
Scheduler dry-run:
- WARNING: Failed to place all allocations.
Task Group "mongodb" (failed to place 1 allocation):
* Constraint "${attr.vault.version} semver >= 0.6.1": 1 nodes excluded by filter
* Constraint "${attr.unique.hostname} = srv1u100": 3 nodes excluded by filter
Jest to taki trochę, hidden feature Nomada, który jak ma problemy z komunikacją ze swoim zintegrowanym Vaultem, to w takim przypadku (kiedy ma w jobspecu cos do roboty właśnie z Vaultem), rzuca komunikatem, że “no chyba masz baaaardzo starego Vaulta”.
Rezultat i co dalej..
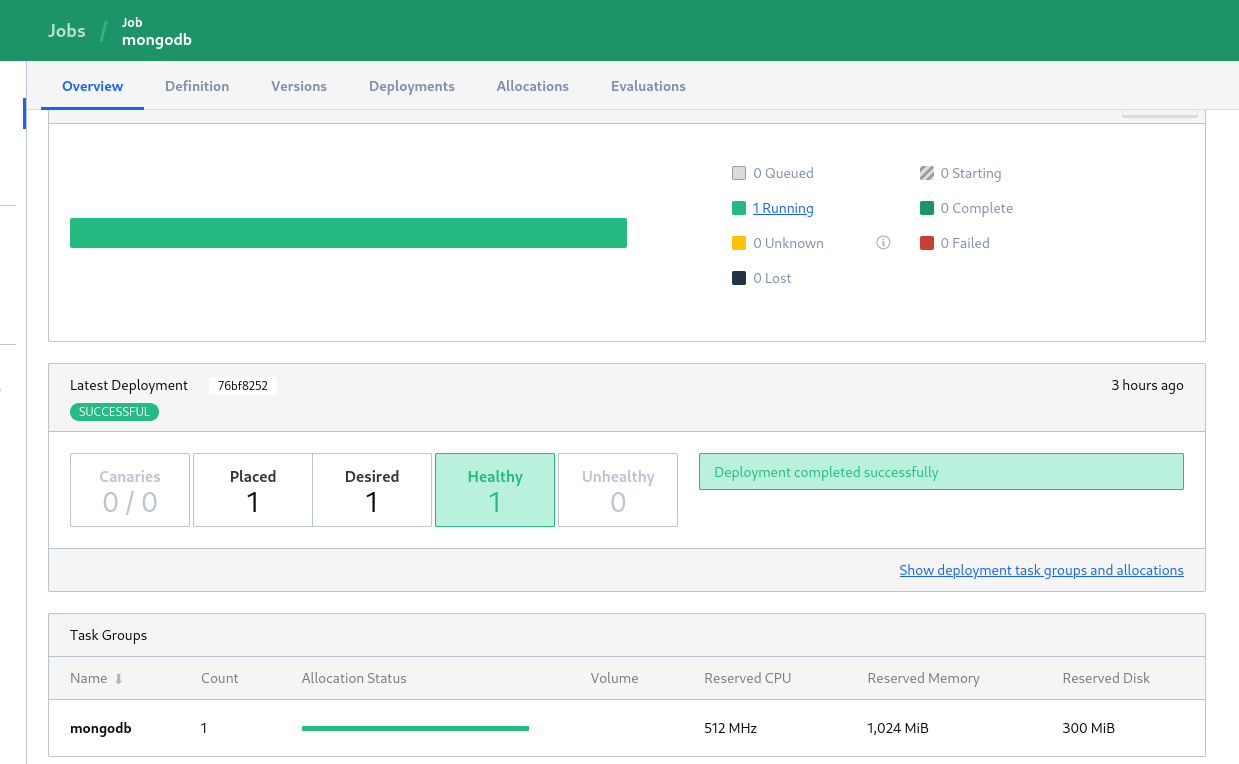
W rezultacie naszych starań dostajemy działąjącą MongoDB, czekającą na swoją aplikację. Sprawdźmy:
Mongo działa i jest “zdrowe”:
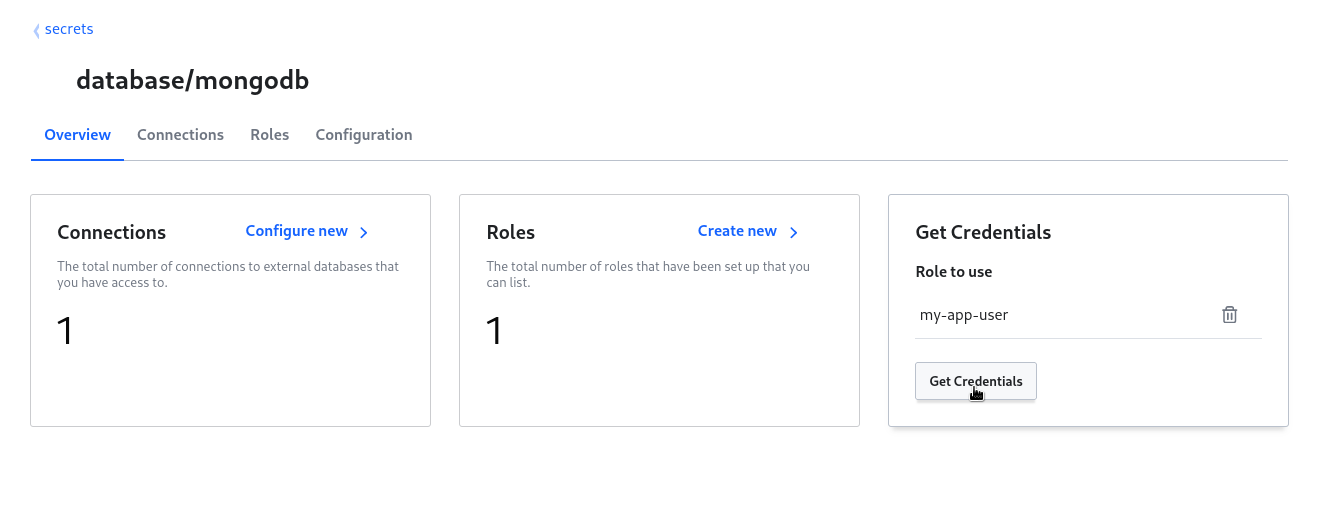
Generujemy sobie login i hasło do interesującej nas bazy dla tej aplikacji, poprzez uruchomiony silnik MongoDB w Vaulcie:
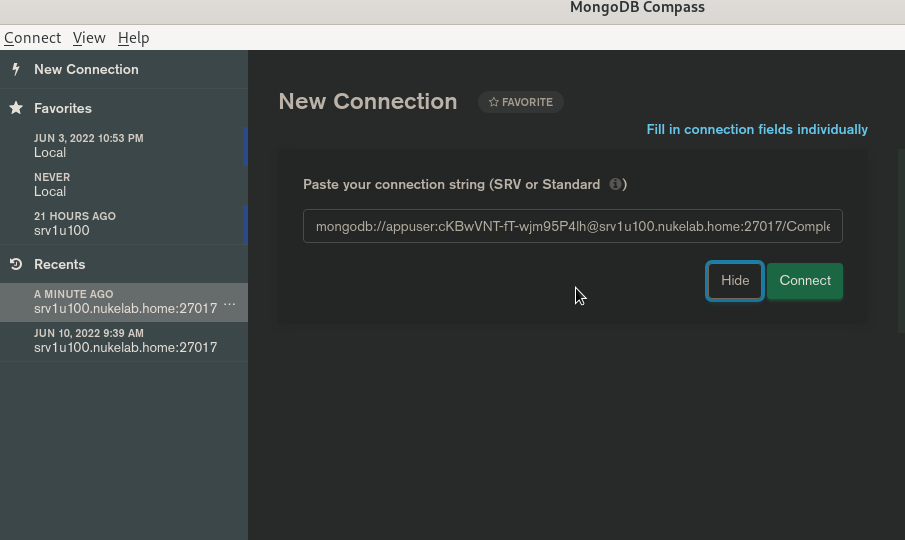
Przy użyciu aplikacji Compass sprawdzamy czy mamy dostęp:
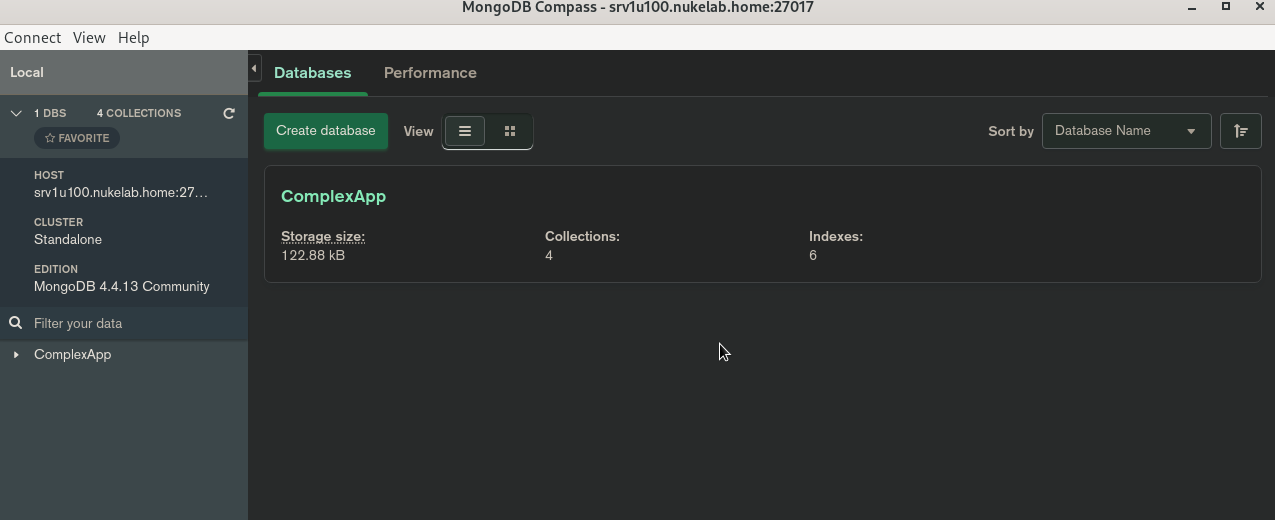
Co dalej?
W kolejnym odcinku, napiszę i pokażę jak uruchamia się i konfiguruje silnik bazodanowy MongoDB w Vaulcie. Opiszę do czego służy i na koniec zrobimy deployment naszej aplikacji, która w podobnie bezpieczny sposób, połączy się z Mongo.