Od ostatniego wpisu upłynęły prawie dwa dni. Tak to już jest, że każdy kolejny wpis jest katalizatorem i przyspieszaczem szarych komórek, powodującym, że “kuleczki” zaczynają się częściej zderzać (jeśli mają dość czasu, na takie fanaberie). :)
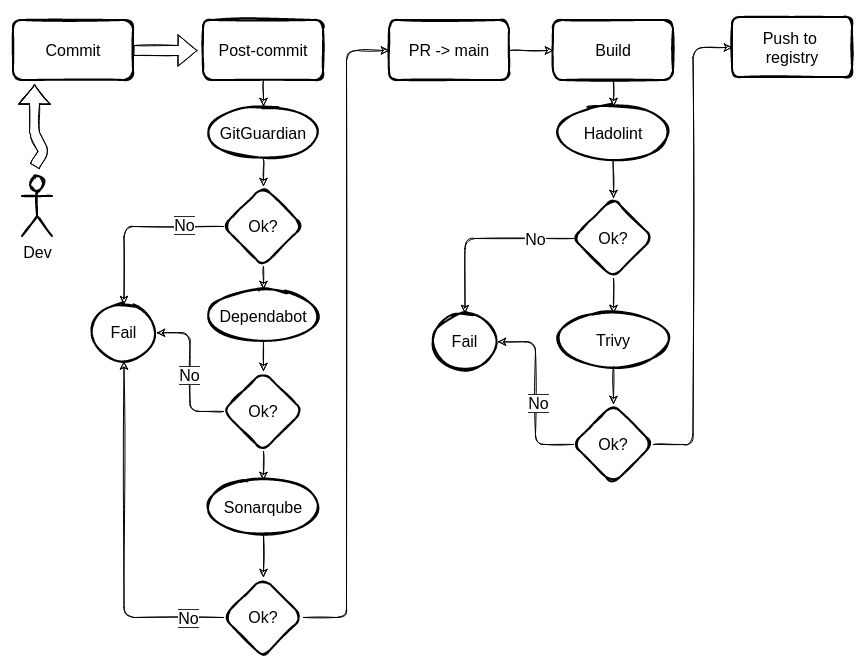
Tym razem zaczęły się częściej zderzać nad poprawną kolejnością poszczególnych etapów sprawdzania komponentów/warstw aplikacji w procesie jej budowania. I od razu tylko nadmienię, że o testach jednostkowych nie zapomniałem. Na razie wydaje mi się, że można podejść do nich elastycznie, i kiedy już nauczę się je pisać, na początek będę je odpalał z VSC przed commitem. Docelowo, chyba powinien to być pierwszy krok etapu “post-commit”. Jeżeli testy nie wyjdą to nie ma po co sprawdzać bezpieczeństwa, bo aplikacja i tak nie zadziała.
Co, jak i dlaczego?
Wybór takich a nie innych narzędzi, podyktowany był faktem iż, wszystkie prócz Dependabota można użyć on-prem.
-
GitGuardian (ggshield) przeczesze całe repozytorium, czy aby nie ma tam jakichś danych uwierzytelniających - czy stosujemy dobrą praktykę “nie-hard-kodowania sikretów” w kodzie aplikacji,
entrypoint.shdockerowym, czy gdziekolwiek indziej. Jeśli coś znajdzie - to działanie GH Action jest przerwane i leci zwrotka z komunikatem, żeby się kolega developer podgarnął i nie oszukiwał. Tę dobrą praktykę uważam za fundamentalną (zaraz po unit-testach), więc jak to nie przejdzie, nie ma sensu sprawdzać dalej. Stąd miejsce na podium. -
Dependabot. Kiedy już się kolega podgarnął, leci sprawdzanie zależności bibliotek aplikacji. Warto zauważyć, że akcja z Dependabotem powinna się kręcić również niezależnie od tego procesu np. raz na tydzień. Usuwanie wykrytych podatności powinno być częścią okresowego przeglądu kodu. Może, też raz na miesiąc, to zależy od stosu technologicznego aplikacji, stopnia skomplikowania i co bardzo ważne istniejącego długu technologicznego (np. stara aplikacja, której utrzymanie traktowano dość woluntarystycznie). Chodzi o to, by przyrosty w czasie nie były za duże, by nie musieć ślęczeć długimi godzinami nad usuwaniem podatności i testowaniem aplikacji. A potem jeszcze ktoś musi przejrzeć PR’a, a jeśli będzie miał 30 zmian do przejrzenia, to również zrobi tego w 15 minut, chyba że pójdzie na skróty, zaryzykuje i klepnie (ang. rubber stamp). Ale wracając.. ten krok służy głównie temu, by wykryć te podatności, na których potem, po zbudowaniu aplikacji, może zatrzymać nas Trivy. Dependabot może być skonfigurowany tak, aby sprawdzał tylko zależności w paczkach produkcyjnych (a nie tych zainstalowanych z
npm i .. --save-dev). Może też nie sprawdzać zależności zagnieżdżonych (wpackage-lok.json) ale znowu, możemy na tym polec później przy Trivy. I tu bym ustawił, że wszelkie CRITICAL/HIGH zatrzymują proces i wysyłają zwrotkę z informacją co należy poprawić (a jeśli sie nie da, bo nie ma remedium, to procedura obsługi wyjątku, tak dobrze przecież znana każdemu bezpiecznikowi i świadomemu programiście :-) ). -
Sonarqube. I tu się żarty kończą, o ile zależy nam na jakości. Sonar jest dość potężnym narzędziem, które można precyzyjnie umieścić w procesie SDLC. Sonar-scanner z akcji githubowej sprawdzi cały kod i zamelduje (przyrostowo) SonarQubowi, co zostało poprawione - bugs, code smells, security issues; Jakie mamy aktualne pokrycie kodu testami jednostkowymi (unit test coverage) i czy to pokrycie mieści się w zadanych progach akceptacji ustawionych dla danego projektu (np. 80%). W Sonarze możemy ustawić tzw. “quality gates” i wymuszać blokadę w zalezności od powagi wykrytej i ocenionej sytuacji - np. bugi “CRITICAL” czy “MAJOR”, pokrycie testów poniżej 80% itd. Podatności wykryte przez Sonarquba są innego rodzaju niż te z Dependabota. Tu automat analizuje statycznie kod i wykrywa te kawałki, które potencjalnie mogą przynieść kłopoty - np. użycie słabego algorytmu szyfrowania, brak nagłówków autoryzujących w obiektach obsługi HTTP itd. Jeśli chodzi o konfigurację jest-a z sonarqubem to jest to trywialne, z mocha nie jest już tak łatwo. Szczegóły zamieszczę w osobnym wpisie.
-
Hadolint. Kiedy nasz kod jest już czyściutki, mięciutki i pachnący jak kaczuszka, możemy przejść do etapu sprawdzania build-a, czyli aplikacji zapakowanej do bazowego obrazu dockerowego (który uprzednio przygotowany, czeka na nas w rejestrze). Hadolint sprawdzi czy trzymamy się dobrych praktyk budowania obrazów dokerowych - czy aby czasem nie można z niego “wyskoczyć” z root-em, czy nie jest za duży. Ten osobnik, chyba jest najbardziej upierdliwy ze wszystkich, np. domaga się aby wszystkie paczki instalowane w obrazie miały podaną wersję explicite. :)
-
Trivy. Prawdziwy, nie znający litości, bezpieczniacki skaner SAST. Doprowadzający do rozpaczy w dwa łyki zimnej już kawy. Korzysta z własnej bazy podatności w oparciu o różne feedy dot. Linuxa, MacOSa, dockera, helm chartów itd. Można skanować system plików i zależności, nieprawidłowe konfiguracje, cały OS, obraz dockerowy z aplikacją. Działa w trybie klient-serwer, tzn. odpalamy zdockeryzowany skaner (klienta), który połączy się z bazą serwera (wisi sobie w Nomadzie), dociągnie aktualizacje do bazy i ..zapewni nam ból głowy. Aby go trochę zmniejszyć, można ustawić by powiadamiał nas tylko o podatnościach CRIT/HIGH (
trivy image --severity HIGH,CRITICAL myapp), a w.trivyignoremożna wpisać jakieś nienaprawialne sygnatury podatności.
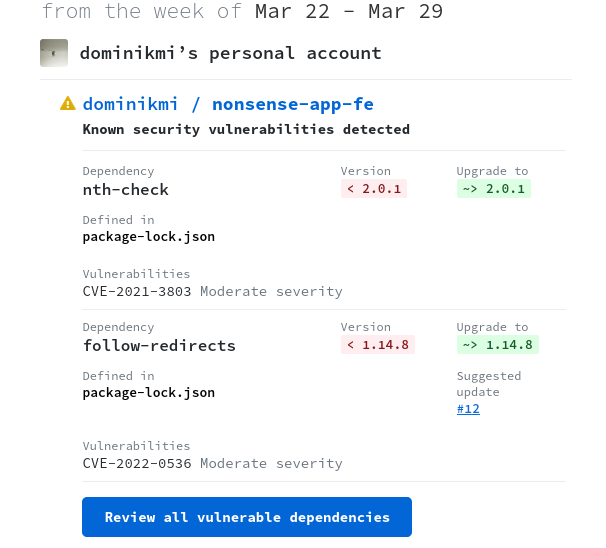
Przykładowe powiadomienie od Dependabota
Podsumowanie
Dobór narzędzi powinien być zdeterminowany platformą CI/CD i możliwościami ich integracji. Póki co, to co wybrałem jest wystarczające do zabawy i budowania wiedzy w tym zakresie. Nie wykluczone, że przedstawiony wyżej proces nie jest ani optymalny, ani wystarczający z punktu widzenia efektywności samego procesu i stopnia bezpieczeństwa jaki powinien zapewniać. Od czegoś jednak trzeba zacząć, by twórczo rozwijać.